Surprising economics of load-balanced systems
摘要
文章设定一个负载均衡系统:有 c 个单线程服务器、前端无限队列,请求到达服从泊松过程、服务时间服从指数分布,并将总流量随 c 线性增加以保持每个服务器平均负载恒定(示例为每服务器 0.8 rps、平均服务时间 1 秒)。作者提出一个直觉问题:随着 c 增大,客户端感知的平均延迟如何变化。 通过排队论中的 M/M/c 模型与 Erlang C 公式分析,结果显示“请求需要排队的概率”会随着 c 增大而下降,因此平均延迟并不会保持不变或变差,而是逐渐趋近于 1 秒的服务时间(对应选项 A)。 文中进一步用 Monte Carlo 模拟说明,这种趋势不仅体现在均值,也同样反映在 p50、p99 等高分位延迟上,没有明显隐藏的尾延迟反转现象。最后讨论该结论对云系统与规模经济的含义:在固定单机吞吐条件下,增加并行服务器规模可以同时改善延迟或提高利用率,但该结论依赖 M/M/c 假设与系统稳定条件(到达率需小于处理能力)。
荐读理由
在你评估负载均衡与扩容方案时,可以据此用排队系统的直觉判断:增加后端节点数并在固定单机负载下扩展规模,往往会显著降低请求进入排队的概率,从而改善整体与尾部延迟,避免把“线性扩容≈延迟不变”的直觉误判为架构结论。
原文
Marc's Blog
About Me
My name is Marc Brooker. I like to build things that work, and do cool stuff. I like building big things. I also dabble in machining, welding, cooking, and skiing.
I am an engineer at Amazon Web Services (AWS) in Seattle, where I work on agentic AI, especially safety and policy for agentic AI. Before that, I worked on EC2, EBS, databases, serverless, and serverless databases. All opinions are my own.
Links
My Publications and Videos @marcbrooker on Mastodon @MarcJBrooker on Twitter
Surprising Economics of Load-Balanced Systems
The M/M/c model may not behave like you expect.
I have a system with c servers, each of which can only handle a single concurrent request, and has no internal queuing. The servers sit behind a load balancer, which contains an infinite queue. An unlimited number of clients offer c * 0.8 requests per second to the load balancer on average. In other words, we increase the offered load linearly with c to keep the per-server load constant. Once a request arrives at a server, it takes one second to process, on average. How does the client-observed mean request time vary with c?
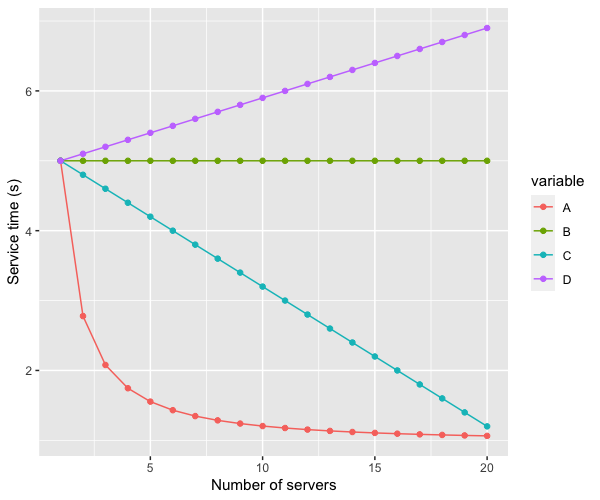
Option A is that the mean latency decreases quickly, asymptotically approaching one second as c increases (in other words, the time spent in queue approaches zero). Option B is constant. Option C is a linear improvement, and D is a linear degradation in latency. Which curve do you, intuitively, think that the latency will follow?
I asked my Twitter followers the same question, and got an interestingly mixed result: 
Breaking down the problem a bit will help figure out which is the right answer. First, names. In the terminology of queue theory, this is an M/M/c queuing system: Poisson arrival process, exponentially distributed client service time, and c backend servers. In teletraffic engineering, it’s Erlang’s delay system (or, because terminology is fun, M/M/n). We can use a classic result of queuing theory to analyze this system: Erlang’s C formula E2,n(A), which calculates the probability that an incoming customer request is enqueued (rather than handled immediately), based on the number of servers (n aka c), and the offered traffic A. For the details, see page 194 of the Teletraffic Engineering Handbook. Here’s the basic shape of the curve (using our same parameters):

Follow the blue line up to half the saturation point, at 2.5 rps offered load, and see how the probability is around 13%. Now look at the purple line at half its saturation point, at 5 rps. Just 3.6%. So at half load the 5-server system is handling 87% of traffic without queuing, with double the load and double the servers, we handle 96.4% without queuing. Which means only 3.6% see any additional latency.
It turns out this improvement is, indeed, asymptotically approaching 1. The right answer to the Twitter poll is A.
Using the mean to measure latency is controversial (although perhaps it shouldn’t be). To avoid that controversy, we need to know whether the percentiles get better at the same rate. Doing that in closed form is somewhat complicated, but this system is super simple, so we can plot them out using a Monte-Carlo simulation. The results look like this:

That’s entirely good news. The median (p50) follows the mean line nicely, and the high percentiles (99th and 99.9th) have a similar shape. No hidden problems.
It’s also good news for cloud and service economics. With larger c we get better latency at the same utilization, or better utilization for the same latency, all at the same per-server throughput. That’s not good news only for giant services, because most of this goodness happens at relatively modest c. There are few problems related to scale and distributed systems that get easier as c increases. This is one of them.
There are some reasonable follow-up questions. Are the results robust to our arbitrary choice of 0.8? Yes, they are1. Are the M/M/c assumptions of Poisson arrivals and exponential service time reasonable for typical services? I’d say they are reasonable, albeit wrong. Exponential service time is especially wrong: realistic services tend to be something more like log-normal. It may not matter. More on that another time.
Update: Dan Ports responded to my thread with a fascinating Twitter thread pointing to Tales of the Tail: Hardware, OS, and Application-level Sources of Tail Latency from SoCC’14 which looks at this effect in the wild.
Footnotes
- Up to a point. As soon as the mean arrival rate exceeds the system’s ability to complete requests, the queue grows without bound and latency goes to infinity. In our case, that happens when the request load exceeds
c. More generally, for this system to be stableλ/cμmust be less than 1, whereλis the mean arrival rate, andμis the mean time taken for a server to process a request.
Similar Posts
05 Aug 2021 » Latency Sneaks Up On You
19 Apr 2021 » Tail Latency Might Matter More Than You Think
19 Jun 2026 » Meet Alice. Alice is impatient.
Something Completely Different
- 24 May 2015 » Sodium Carbonate, and Ramenized Pasta
Marc Brooker The opinions on this site are my own. They do not necessarily represent those of my employer. marcbrooker@gmail.com
This work is licensed under a Creative Commons Attribution 4.0 International License.
这条对你有帮助吗?